
지난 번에 RNN을 살펴보았다.
RNN(Recurrent Neural Network)은 한 단계의 출력이 다음 단계의 입력으로 피드백 되어 순차적 데이터를 처리합니다.
이를 통해 RNN은 보통 시계열 데이터의 시간적 특징을 파악하고 과거 컨텍스트를 기반으로 출력을 뱉는다.
하지만 RNN은 이전 입력에 대한 중요한 정보를 쉽게 잊어버릴 수 있다는 단점을 가지고 있다.
이번 포스팅에서는 이런 RNN을 대신할 LSTM(Long Short-Term Memory)에 대해 알아보자.
LSTM에 대한 아주 디테일한 내용과 수학이 궁금하다면 https://blog.floydhub.com/long-short-term-memory-from-zero-to-hero-with-pytorch/을 방문해보자.
LSTM 개요
LSTM(Long Short-Term Memory)은 기존 RNN에서 발생할 수 있는 vanishing gradients 문제를 방지하기 위해 설계된 특수한 유형의 RNN이다.
LSTM은 입력 데이터를 기반으로 정보를 선택적으로 기억하거나 잊을 수 있는 메모리 셀이 도입되었다.
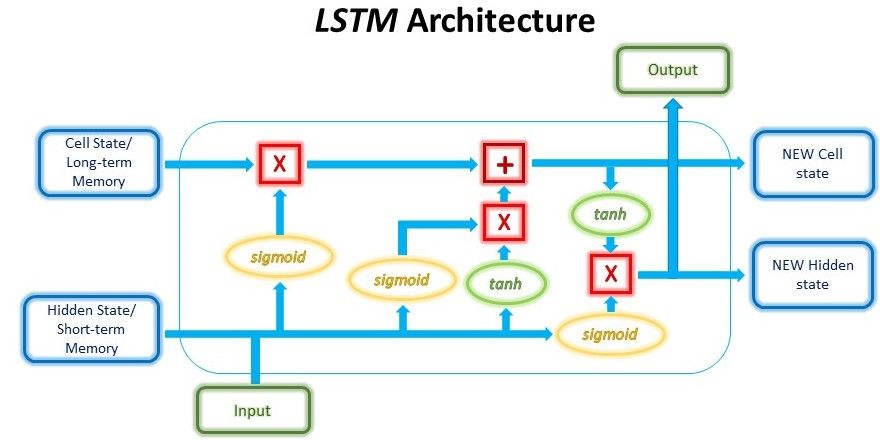
Long Short-Term Memory라는 이름에서 알 수 있는 것처럼 이 메모리 셀에는 long-term 메모리(장기 메모리)와 short-term 메모리(short-term scratchpad라고도 부름, 단기 메모리)가 있다.
장기 메모리는 중요한 정보를 유지하고 단기 메모리는 짧은 시간 스케일에서 데이터의 상관 관계를 유지한다.
그런 다음 셀은 게이트를 통과하여 정보를 선택적으로 통과시키는데 이러한 게이트는 훈련이 필요하다.
게이트에는 input gate, forget gate, output gate가 있는데 이러한 게이트가 어떤 역할을 하는지 자세히 살펴보자.
Input Gate
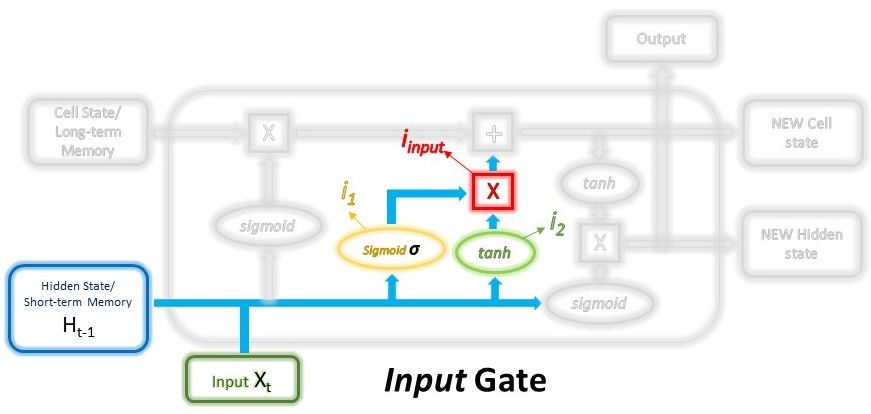
Input gate는 장기 메모리에 어떤 새로운 정보를 저장할지 결정한다.
이 게이트는 현재 입력과 이전 시간 단계의 단기 메모리를 입력으로 받아 작동한다.
Input gate는 현재 입력과 단기 메모리의 정보를 시그모이드 함수에 전달하여 0와 1사이의 값으로 변환된다.
0은 정보가 중요하지 않음을 나타내고 1은 정보가 중요하고 사용된다는 것을 나타낸다.
역전파를 통해 훈련됨에 따라 시그모이드의 가중치는 이러한 기능 즉, 덜 중요한 정보는 거르고 중요한 정보가 통과되게끔 학습된다.
Tanh는 단기 메모리의 정보와 현재 입력을 통해 네트워크를 조절하기 위한 계층이다.
이제 시그모이드의 출력과 Tanh의 출력이 서로 곱해져 장기 메모리와 출력할 정보를 나타낸다.
Forget Gate

Forget Gate는 장기 메모리의 어떤 정보를 계속 보관하거나 폐기할지를 결정한다.
이 게이트의 역할은 장기 메모리의 정보에 현재 입력과 단기 메모리의 정보를 통해 생성된 forget vector을 통해 수행된다.
Input Gate와 Forget Gate의 출력은 다음 셀로 전달될 장기 메모리의 새 버전으로 추가된다.
새롭게 만들어진 장기 메모리의 데이터는 출력 게이트에도 사용된다.
Output Gate

Output gate는 현재 입력과 단기 메모리의 정보 및 새 버전의 장기 메모리의 데이터를 사용하여 출력과 다음 단계에서 사용될 새로운 단기 메모리를 출력한다.
이렇게 세 개의 Gate로 LSTM이 작동한다.
게이트 동작의 많은 부분에 대한 설명은 https://blog.floydhub.com/long-short-term-memory-from-zero-to-hero-with-pytorch/을 참고하였다.
PyTorch로 LSTM 구현하기
복잡하긴 하지만 파이토치로 LSTM의 구현은 간단하다.
import torch
import torch.nn as nn
class MyLSTM(nn.Module):
def __init__(self, n_input=20, n_hidden=128, n_layers=3, n_outputs=10):
super(MyLSTM, self).__init__()
self.lstm = nn.LSTM(n_input, n_hidden, n_layers, batch_first=True)
self.decode = nn.Linear(n_hidden, n_outputs)
def forward(self, x, skip_decoding=False):
output, hidden = self.lstm(x) # automatic zeros for initial hidden state
if not skip_decoding:
output = self.decode(output[:,-1,:]) # take only the last hidden state
return output, hiddenLSTM의 작동과 훈련은 이전 글의 RNN에서 살펴본 것과 매우 유사하기 때문에 샘플 데이터 및 훈련 코드는 이전 글을 참고하자.
개념이 복잡할수록 코드는 모듈을 가져다쓰면 되기 때문에 오히려 간단하다.
다음 살펴볼 머신러닝 주제는 Generative Adversarial Network이다.
눈으로 직접 확인할 수 있는게 많은 주제이므로 기대해도 좋을 것이다.
'머신 러닝 > Machine Learning' 카테고리의 다른 글
| [Machine Learning] PyTorch로 DCGAN 구현하기 (Deep Convolutional Generative Adversarial Network) (0) | 2023.03.16 |
|---|---|
| [Machine Learning] PyTorch로 GAN 구현하기 (Generative Adversarial Network) (0) | 2023.03.15 |
| [Machine Learning] PyTorch로 RNN(순환 신경망) 구현하기 (0) | 2023.03.09 |
| [Machine Learning] PyTorch로 ResNet 구현하기 (Residual Network) (1) | 2023.03.07 |
| [Machine Learning] PyTorch로 Regularization(정규화) 직접 해보기 (1) | 2023.03.06 |