
본 블로그의 Machine Learning 카테고리에서는 주로 이미지를 처리하는 내용을 다루었다.
각각의 이미지 데이터는 하나의 독립적인 데이터였다.
하지만 이런 패러다임에 맞지 않는 데이터는 어떻게 처리할 수 있을지 생각해보자.
텍스트로 이루어진 문장은 짧거나 길어질 수도 있고, 그 사이의 단어는 문맥이나 의미를 바꿀 수 있다.
자율 주행 자동차가 인식하는 주변 환경에 대한 비디오는 다른 자동차나 사람의 궤적을 찾고 예측해야 한다.
이때 시퀀스(sqeuences)라는 개념이 등장한다.
Sequences
Sequences(시퀀스)는 특정 순서로 배열된 데이터 포인트 집합을 말한다.
말이 어렵지 사실 자연어 처리에서 시퀀스의 개념을 간단히 이해할 수 있다.
자연어 처리에서 시퀀스는 문장이나 단락이다.
이때 각 단어가 데이터 포인트가 되고 특정 순서는 문장의 의미를 뜻한다고 볼 수 있다.
시퀀스로 작동하는 모델을 통해 간단하게는 영화의 리뷰를 긍정적인 반응인지 부정적인 반응인지 분류할 수 있다.
조금 복잡한 모델로 시계열에서 다음에 올 요소를 예측할 수 있다.
예를 들어, 과거의 데이터로 주식 가격을 예측해 볼 수 있다. (책임지지는 않는다.)
또한 요즘 유행하는 챗GPT와 같이 입력 문장이 주어졌을 때 다음 단어를 예측할 수 있다.
더 복잡하게는 문장을 입력받아 해당 문장을 말하는 사람을 모방한 오디오 파일을 생성하거나, 한 언어로 문장을 사용해서 다른 언어로 번역할 수 있다.
특히 이것을 seq2seq(시퀀스 투 시퀀스)라고 한다.
Recurrent Neural Network
임이의 길이의 시퀀스를 네트워크의 입력으로 주기 위해서는 우리가 기존에 쓰던 레이어를 수정해야한다.
먼저 데이터를 단계별로 나눠야 한다.
(나눈다는 것이 주식이나 오디오에 대한 시간 단계일 수도 있고, 어떤 텍스트에 대한 단어순일 수도 있다.)
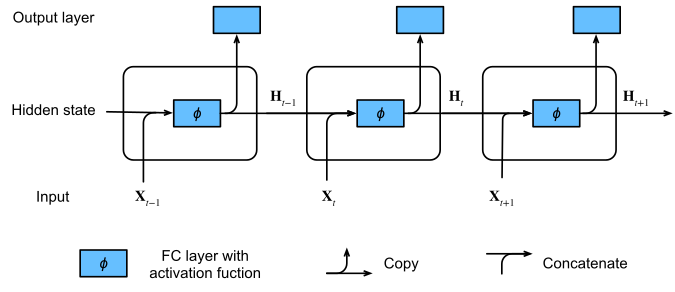
단계가 시간이든 단어순이든 어떤 단계이든 일단 설명을 위해 시간이라고 하자.
각 시간 단계에 대해, 우리는 평소처럼 한 단계에 대한 입력을 전달하지만 우리가 만들 모델은 두 개의 출력을 뱉을 것이다.
각각 Hidden state와 Output인데 Output은 우리가 아는 네트워크의 출력이다.
Hidden state는 다음 단계의 입력으로 전달되는 상태(state)이다. (state을 한국어로 번역하기 참 애매하다.)
각 입력에 대한 계산에서 hidden state가 계속 발생하기 때문에 우리는 이 과정을 recurrent computation이라고 부르고 이런 구성의 뉴런을 recurrent neurons, 이것들로 만들어진 네트워크를 Recurrent Neural Network(RNN)이라고 부른다.
히든 레이어는 아래 그림처럼 한 층을 가질 수도 있지만,
(위의 그림을 시계방향으로 90도 회전시킨 그림이다.)

두 히든 레이어를 갖도록 설계할 수도 있다.
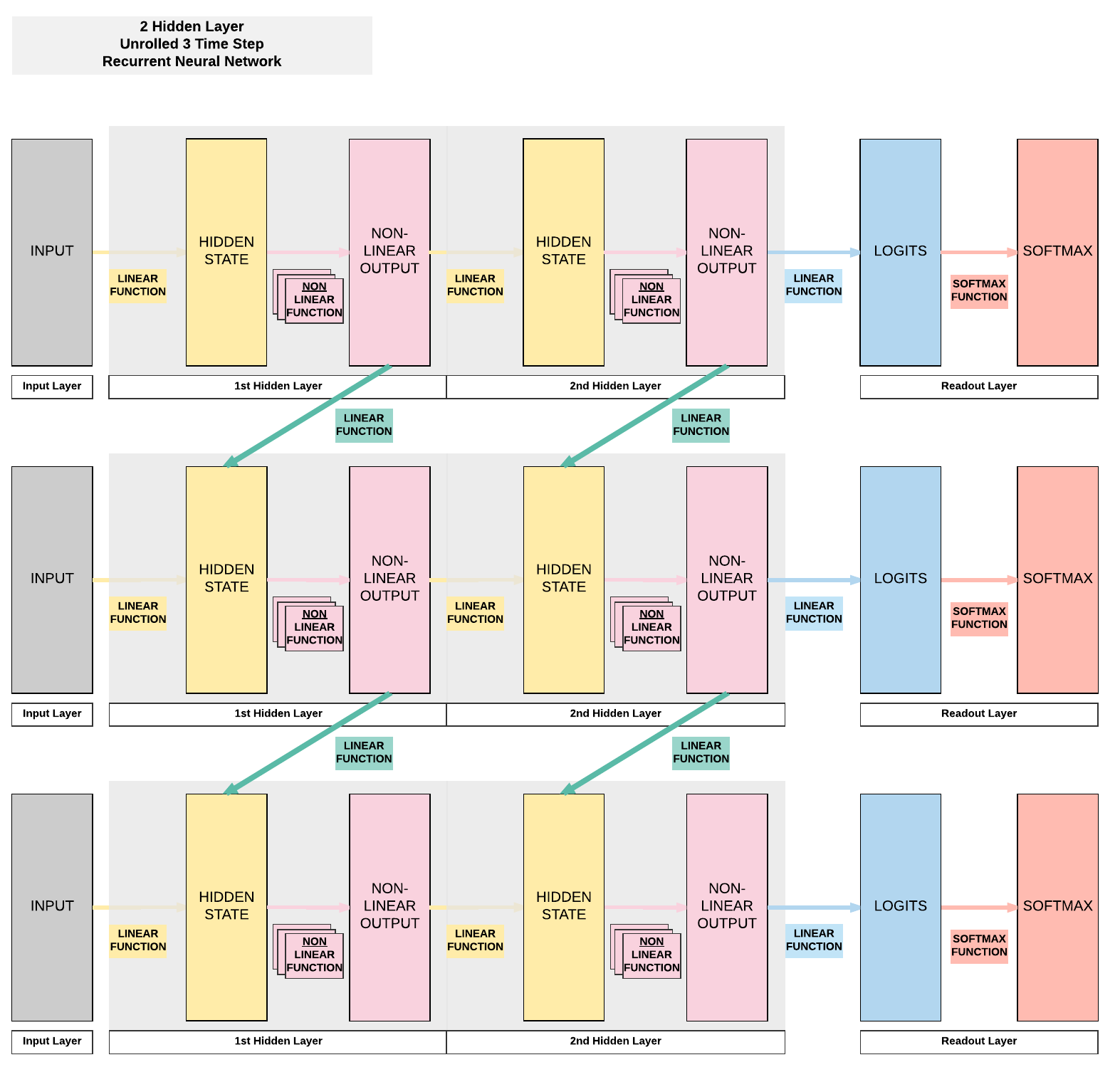
그럼 이제 직접 RNN을 만들어보자.
이번 코드는 PyTorch Tutorial에서 많이 가져왔다.
코드는 거의 그대로 가져오되 중간중간 이해를 돕기 위한 프린트 구문과 주석을 추가하였다.
PyTorch로 RNN 구현하기
먼저 RNN부터 만들어보자.
코드는 매우 직관적이고 간단하다.
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.h2o = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = torch.tanh(self.i2h(combined))
output = self.h2o(hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)RNN은 input_size, hidden_size 및 output_size의 세 가지 인수를 받는다.
input_size는 입력 벡터의 크기이고 hidden_size는 히든 스테이트의 벡터의 크기이며 output_size는 출력 벡터의 크기이다.
i2h, h2o 레이어는 nn.Linear 함수를 사용한다.
i2h레이어는 입력 벡터와 히든 스테이트 벡터를 입력으로 받아 새로운 히든 스테이트 벡터를 뱉는다.
h2o레이어는 히든 스테이트 벡터를 입력으로 사용하여 output을 출력한다.
forward에서 먼저 입력과 히든 상태를 cat으로 합친다.
그 다음 i2h레이어를 통과한 후 출력에 하이퍼 탄젠트 활성화 함수를 적용한다.
이제 그 결과를 h2o레이어를 통해 전달하여 업데이트된 히든 스테이트와 output이 함께 출력된다.
initHidden는 처음 히든 상태를 크기가 (1, hidden_size)의 0으로만 이루어진 텐서로 초기화한다.
이제 네트워크는 만들었으니 데이터를 다운로드 받자.
주피터 노트북이나 주피터 랩에서 작업 중이라면 아래 코드를 실행하자.
!wget https://download.pytorch.org/tutorial/data.zip
!unzip data.zip참고로 줄 앞에 !느낌표를 먼저 쓰면 이 코드는 터미널에서 스크립트를 실행한다는 말이다.
데이터는 각 국가의 이름 파일로 있고, 파일의 각 줄은 국가별 "성"이다.
텍스트 파일이니 직접 파일을 열어서 확인해도 좋다.
이제 이름을 유니코드에서 ASCII로 변환하는 함수를 만들자.
import unicodedata
import string
from glob import glob
files = glob("data/names/*.txt")
# restrict the letters we consider to ascii (plain english) only
all_letters = string.ascii_letters+" .,;'"
n_letters = len(all_letters)
# helper function to convert unicode to ascii
def unicodeToAscii(s):
return ''.join(c for c in unicodedata.normalize("NFD", s)
if unicodedata.category(c) != "Mn" and c in all_letters)어떤 코드를 만든 것인지 아래를 통해 확인해보자.
print(all_letters)
print(n_letters)
print(unicodeToAscii('Ślusàrski'))위 코드를 실행하면 아래와 같은 출력을 얻는다.
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'
57
Slusarski이게 무슨 짓을 한 거냐면 마지막처럼 Ślusàrski을 로마자 Slusarski로 바꾼 것이다.
함수를 만들었으니 파일의 모든 이름을 로마자로 변환해주자.
import os
# holds a dictionary from language name -> list of names from that language
category_lines = {}
# list of all the languages we consider
all_categories = []
# read the list of names, process through our unicode->ascii function
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
# run the functions over all files
for filename in files:
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
# our output will be a vector n_categories long corresponding to
# the network's assigned probability for each language
n_categories = len(all_categories)변환이 완료되었다.
이제 아래 코드로 나라의 개수가 몇 개인지(카테고리 수), 각 나라의 이름이 무엇인지, 한국 성에는 어떤 것들이 있는지 확인해보자.
print(n_categories, all_categories)
print(category_lines['Korean'][:])그러면 아래와 같은 출력이 나온다.
너무 길어서 ...으로 줄였다.
18 ['Arabic', 'Chinese', ... , 'Korean', ... , 'Vietnamese']
['Ahn', 'Baik', 'Bang', ... , 'Yun']
아직 더 데이터를 가공해야한다.
이제 각 이름들의 스펠링을 원-핫 벡터로 만들자.
무슨 말인지는 코드를 직접 보며 설명하겠다.
import torch
# the position we set to 1 is just the index of the letter in the all_letters array
def letterToIndex(letter):
return all_letters.find(letter)
# create a tensor shape (len(all_letters),) with the appropriate index on
def letterToTensor(letter):
tensor = torch.zeros(1,n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
# create a tensor [len(word), 1=batch_size, len(all_letter)] and set each letter
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor세 가지 함수를 만들었는데 어떤 일을 하는 함수인지 직접 돌려보자.
# test the functions
print(letterToIndex("J"))
print(letterToTensor('J'))
print(lineToTensor("Jones").shape)
print(lineToTensor("Jones"))첫 줄의 출력은 35일 것이다.
아까 만든 all_letters 즉, abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'에서 J가 35번째에 있다는 뜻이다. (우리가 셀 때는 36번째이지만 컴퓨터는 0부터 센다)
두 번째 줄의 출력은 모든 수가 0이지만 35번째에 1만 있는 J에 대한 원-핫 벡터이다.
세 번째는 글자 대신 단어를 넣은 것인데 어렵지 않으니 네 번째 줄의 출력을 직접 확인해보면서 이해해보자.
참고로 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'의 길이는 57이다.
이제 57개의 입력, 128의 히든 사이즈, 국가의 개수인 n_categories(18개)을 가지는 RNN을 만들자.
그리고 아무 이름이나 하나 넣어보자.
# create a tensor from a name, and pass the first letter through the rnn
rnn=RNN(57,128,n_categories)input = lineToTensor("Albert")
hidden = rnn.initHidden()
output, hidden = rnn(input[0], hidden)
# if everything is working we should have some output
print(output.shape)
print(output)
print(hidden.shape)출력은 아래와 같다. (텐서 안의 숫자는 당연히 다를 수 있다.)
torch.Size([1, 18])
tensor([[-0.0678, 0.0772, 0.0670, 0.0577, 0.0616, -0.0769, 0.1187, 0.0038,
-0.0395, 0.0155, -0.0044, 0.0491, 0.0113, 0.0639, -0.1044, -0.0524,
0.0487, -0.0399]], grad_fn=<AddmmBackward0>)
torch.Size([1, 128])위에서부터 18개의 카테고리, 히든 스테이트와 히든 스테이트의 사이즈를 나타낸다.
이제 랜덤하게 이름을 뽑는 함수를 만들자.
import random
# pick a random language, pick a random name from that language,
# convert to a tensor, with corresponding output index for the language
def randomTrainingExample():
category = random.choice(all_categories)
line = random.choice(category_lines[category])
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor각 요소들이 궁금하면 한번 돌려보자.
for i in range(5):
category, line, category_tensor, line_tensor = randomTrainingExample()
print('category =', category, '/ line =', line, '/ category_tensor =', category_tensor)출력은 아래와 같다.
category = Korean / line = Hwang / category_tensor = tensor([16])
category = Korean / line = Hyun / category_tensor = tensor([16])
category = Japanese / line = Ichimonji / category_tensor = tensor([3])
category = Dutch / line = Snider / category_tensor = tensor([15])
category = German / line = Kistler / category_tensor = tensor([1])이제 네트워크도 만들었고 데이터에 대한 모든 준비가 다 끝났다.
트레이닝하는 코드를 만들어보자.
criterion = nn.CrossEntropyLoss()
opt = torch.optim.Adam(rnn.parameters())
def train(category_tensor, line_tensor):
opt.zero_grad()
hidden = rnn.initHidden()
# pass the tensor through one letter at a time, keeping track of the hidden state
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
# calculate the loss on the final output
loss = criterion(output, category_tensor)
# pytorch keeps track of the computational graph, so will backpropagate
# through the hidden state updates
loss.backward()
# update the network based on the example
opt.step()
return output, loss.item()
이제 100,000개의 무작위 샘플로 훈련하면서 1,000개마다 평균 로스를 추적하며 RNN을 트레이닝 시켜보자.
import time
import math
n_iters = 100000
print_every = 5000
plot_every = 1000
# Keep track of losses for plotting
current_loss = 0
all_losses = []
def categoryFromOutput(output):
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
# Print iter number, loss, name and guess
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else '✗ (%s)' % category
print('%d %.4f %s / %s %s' % (iter, loss, line, guess, correct))
# Add current loss avg to list of losses
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0위 트레이닝 루프에 대한 내 훈련 과정은 아래와 같다.
5000 2.5493 Silverstein / Russian ✗ (German)
10000 0.6590 Natalenko / Russian ✓
15000 1.0978 Pharlain / Irish ✓
20000 1.5474 Koch / Czech ✗ (German)
25000 1.9919 Eales / Portuguese ✗ (English)
30000 0.0474 Corti / Italian ✓
35000 1.3001 Klein / Dutch ✓
40000 2.0860 Hardy / Russian ✗ (French)
45000 3.2698 Serafim / Polish ✗ (Portuguese)
50000 0.0050 Bakhmetov / Russian ✓
55000 2.6526 Kim / Korean ✗ (Vietnamese)
60000 0.0160 Zdunowski / Polish ✓
65000 1.2433 Galkus / Greek ✗ (Russian)
70000 2.3815 Nemoto / Italian ✗ (Japanese)
75000 0.3780 Hoshino / Japanese ✓
80000 0.6679 Yeo / Korean ✓
85000 1.4512 Redden / Dutch ✗ (English)
90000 0.8271 Jordan / Polish ✓
95000 0.8989 Hunter / Scottish ✓
100000 0.7771 Kastner / German ✓로그를 보며 안 사실인데 베트남에도 Kim씨가 사나 보다.
저장한 비용함수 값도 출력해보자.
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)
이제 confusion matrix을 출력해보자.
10,000개의 무작위 예제를 사용하여, 한 축에는 실제 레이블, 다른 축에는 네트워크가 추측하는 결과를 행렬을 표시한다.
이 매트릭스는 네트워크가 주로 헷갈려하는 나라를 확인하기 위해 사용할 수 있다.
# Keep track of correct guesses in a confusion matrix
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000
# Just return an output given a line
def evaluate(line_tensor):
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
# Go through a bunch of examples and record which are correctly guessed
for i in range(n_confusion):
category, line, category_tensor, line_tensor = randomTrainingExample()
output = evaluate(line_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
# Normalize by dividing every row by its sum
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()위 코드를 실행하면 confusion matrix가 나온다.
가운데 박스가 샛노랄수록 잘 예측한다는 이야기고 파래질수록 다른 국가와 헷갈리고 있다는 것이다.
예를 들어, 중국 이름을 한국 이름과 헷갈려하고 특히 그리스 이름을 잘 구분하고 있다. (그리스 축구 선수 이름을 떠올려보자. 뭐 하나 안 특이한 선수가 없다.)
영어는 다른 국가와 비슷한 이름이 많은지 결과가 형편없다.

직접 이름을 넣어서 이 이름을 어떻게 예측하는지 출력해볼 수도 있다.
이름을 넣어서 RNN이 입력받은 이름을 어떤 국가 예측하는지 상위 3개국과 각 국가별로 추측하는 확률이 나오도록 만들어 테스트해보자.
def predict(input_line, n_predictions=3):
print('\n> %s' % input_line)
with torch.no_grad():
output = torch.softmax(evaluate(lineToTensor(input_line)),1)
# Get top N categories
topv, topi = output.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print('(%.3f) %s' % (value, all_categories[category_index]))
predictions.append([value, all_categories[category_index]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')Dovesky, Jackson, Satoshi을 넣으면 다음과 같이 나온다.
> Dovesky
(0.988) Russian
(0.010) Czech
(0.001) English
> Jackson
(0.681) Scottish
(0.146) English
(0.122) Russian
> Satoshi
(0.947) Japanese
(0.031) Polish
(0.016) Italian하지만 이런 RNN도 먼저 입력된 데이터를 서서히 잊는 등의 한계가 있다.
다음엔 이런 문제를 해결해준 좀더 발전된 RNN 중 하나인 LSTM(Long Short Term Memory)에 대해 알아보자.